
GPU Architecture
Using GPGPU-Sim, my research group explored numerous ways to improve the architecture of GPUs when running non-graphics applications. The details of these studies can be found in the papers listed below. Briefly, early on we explored how to improve the performance of applications that include branches, introducing a technique called dynamic warp formation (DWF). The paper introducing DWF has now been cited over 500 times. We also explored how to design memory access schedulers and on-chip interconnects for GPUs. We then explored how to support transactional memory and cache coherence on GPUs. These works were recognized by IEEE Micro Magazine in their annual "Top Picks" issue. We later introduced a technique for improve performance of memory intensive applications, known as cache concious wavefront scheduling (CCWS), which was selected both as an IEEE Micro "Top Picks" and as a Communications of the ACM "Research Highlight". We explored the interaction of synchronization and branch handling proposing a mechanism similar to that introduced in NVIDIA's Volta architecture. Our most recent work introduces a programming model, EDGE, to enable GPUs to be more independent of CPUs inside a datacenter.
Talks
GPU Computing Architecture (short course taught at 2015 HiPEAC Summer School)
Publications
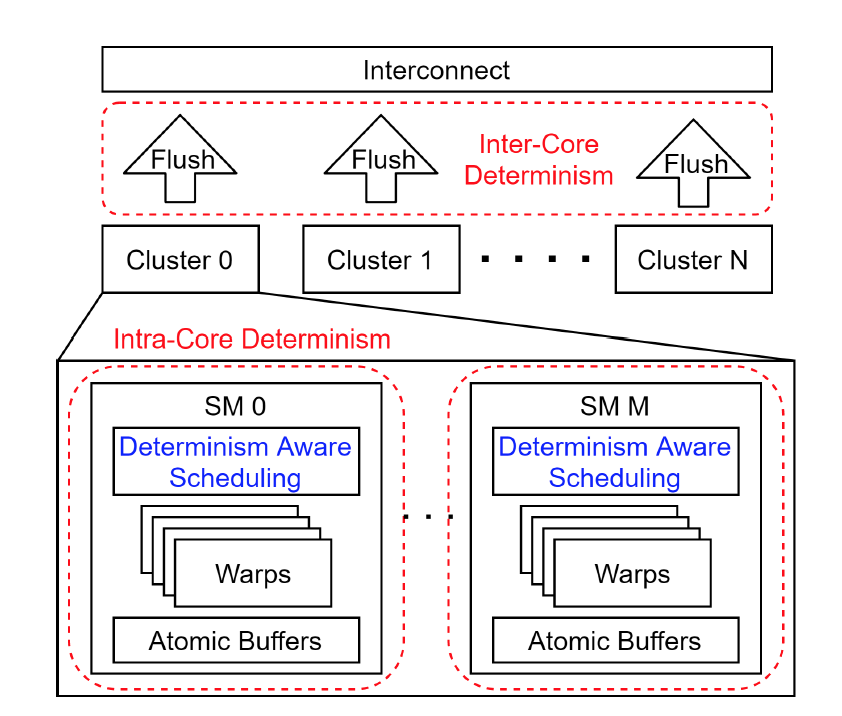 |
Yuan Hsi Chou, Christopher Ng, Shaylin Cattell, Jeremy Intan, Matthew D. Sinclair, Joseph Devietti, Timothy G. Rogers, Tor M. Aamodt, Deterministic Atomic Buffering, In proceedings of the 53rd IEEE/ACM International Symposium on Microarchitecture (MICRO), October 17-21, 2020 Athens, Greece. (acceptance rate: 82/422 ≈ 19.4%) Videos: Full talk, Lightning talk |
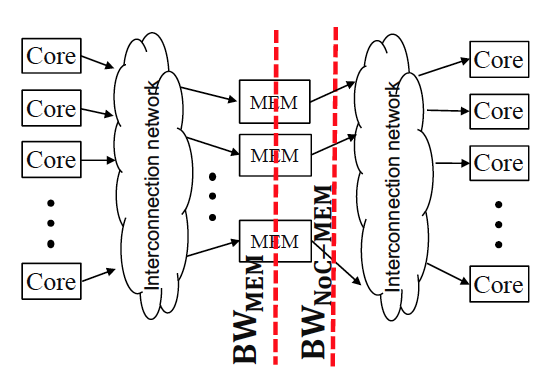 |
Jiho Kim, Sanghun Cho, Minsoo Rhu, Ali Bakhoda, Tor M. Aamodt, John Kim, Bandwidth Bottleneck in Network-on-Chip for High-Throughput Processors, In proceedings of the ACM/IEEE International Conference on Parallel Architectures and Compilation Techniques (PACT 2020), Oct 5-7, 2020. (poster presentation) |
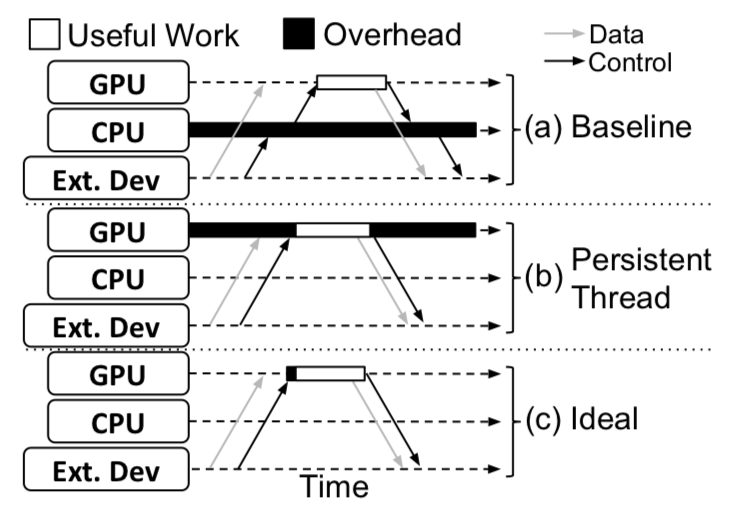 |
Tayler Hetherington, Maria Lubeznov, Deval Shah, Tor M. Aamodt, EDGE: Event-Driven GPU Execution, In proceedings of the ACM/IEEE International Conference on Parallel Architectures and Compilation Techniques (PACT 2019), Seattle, WA, September 21-25, 2019. |
 |
Tor M. Aamodt, Wilson Wai Lun Fung, Timothy G. Rogers, General-Purpose Graphics Processor Architectures, Morgan & Claypool Publishers, 140 pages, May 2018. |
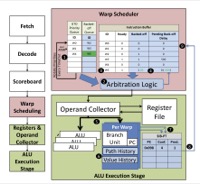 |
Ahmed ElTantawy, Tor M. Aamodt, Warp Scheduling for Fine-Grained Synchronization, In proceedings of the 24th IEEE International Symposium on High-Performance Computer Architecture (HPCA-20), February 24-28 2018, Vienna, Austria. |
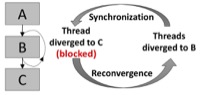 |
Ahmed ElTantawy, Tor M. Aamodt, MIMD Synchronization on SIMT Architectures, In proceedings of the ACM/IEEE Int'l Symposium on Microarchitecture (MICRO'16), Taipei, Taiwan, Oct. 15-19, 2016. (acceptance rate: 61/288 ≈ 21.2%) |
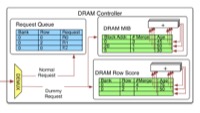 |
Dongdong Li, Tor M. Aamodt, Inter-core Locality Aware Memory Scheduling, in IEEE Computer Architecture Letters, vol. 15, no. 1, pp. 25-28, Jan.-June 2016. |
 |
Timothy G. Rogers, Mike O'Connor, Tor M. Aamodt, Learning Your Limit: Managing Massively Multithreaded Caches Through Scheduling, in Communications of the ACM, vol. 57, no. 12, pp. 91-98, December 2014. |
 |
Inderpreet Singh, Arrvindh Shriraman, Wilson W. L. Fung, Mike O'Connor, Tor M. Aamodt, Cache Coherence for GPU Architectures, IEEE Micro, Special Issue: Micro's Top Picks from 2013 Computer Architecture Conferences, Vol. 34, No. 3, pp. 69-79, May/June 2014. |
 |
Ahmed ElTantawy, Jessica Wenjie Ma, Mike O'Connor, Tor M. Aamodt, A Scalable Multi-Path Microarchitecture for Efficient GPU Control Flow, In proceedings of the 20th IEEE International Symposium on High-Performance Computer Architecture (HPCA-20), pp. 248 - 259, Orlando, FL, February 15-19, 2014. |
 |
Wilson W. L. Fung, Tor M. Aamodt, Energy Efficient GPU Transactional Memory via Space-Time Optimizations, in proceedings of the 46th IEEE/ACM International Symposium on Microarchitecture (MICRO-46), pp. 408-420, Davis, CA, December 7-11, 2013. (acceptance rate: 39/239 ≈ 16.3%), simulator code, slides |
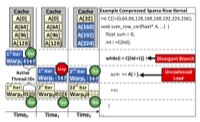 |
Timothy G. Rogers, Mike O'Connor, Tor M. Aamodt, Divergence-Aware Warp Scheduling, in proceedings of the 46th IEEE/ACM International Symposium on Microarchitecture (MICRO-46), pp. 99-110, Davis, CA, December 7-11, 2013. (acceptance rate: 39/239 ≈ 16.3%), slides |
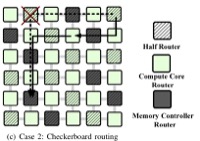 |
Ali Bakhoda, John Kim, Tor M. Aamodt, Designing On-Chip Networks for Throughput Accelerators, ACM Transactions on Architecture and Code Optimization (TACO), Vol. 10, No. 3, Article 21, September 2013. |
 |
Jingwen Leng, Tayler Hetherington, Ahmed ElTantawy, Syed Gilani, Nam Sung Kim, Tor M. Aamodt, Vijay Janapa Reddi, GPUWattch: Enabling Energy Optimizations in GPGPUs, In proceedings of the ACM/IEEE International Symposium on Computer Architecture (ISCA 2013), pp. 487-498, Tel-Aviv, Israel, June 23-27, 2013. (acceptance rate: 56/288 ≈ 19.4%), GPUWattch is included in GPGPU-Sim 3.2.1 onward |
 |
Timothy G. Rogers, Mike O'Connor, Tor M. Aamodt, Cache-Conscious Thread Scheduling for Massively Multithreaded Processors, IEEE Micro, Special Issue: Micro's Top Picks from 2012 Computer Architecture Conferences, Vo. 33, No. 3, pp. 78-85, May/June 2013. |
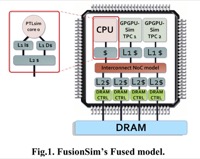 |
Vitaly Zakharenko, Tor M. Aamodt, Andreas Moshovos, Characterizing the Performance Benefits of Fused CPU/GPU Systems Using FusionSim, Design, Automation and Test in Europe (DATE), pp. 685-688, Grenoble, France, 18-22 March, 2013. (interactive presentation) FusionSim website |
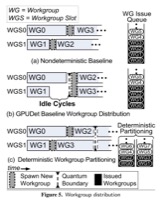 |
Hadi Jooybar, Wilson W. L. Fung, Mike O'Connor, Joseph Devietti, Tor M. Aamodt, GPUDet: A Deterministic GPU Architecture, In proceedings of the Eighteenth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2013), pp. 1-12, Houston, Texas, March 16-20, 2013. (acceptance rate: 44/191 ≈ 23.0%) slides, simulator code+benchmarks |
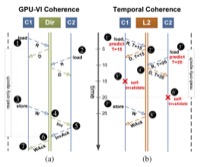 |
Inderpreet Singh, Arrvindh Shriraman, Wilson W. L. Fung, Mike O'Connor, Tor M. Aamodt, Cache Coherence for GPU Architectures, In proceedings of the 19th IEEE International Symposium on High-Performance Computer Architecture (HPCA-19), pp. 578-590, Shenzhen, China, February 23-27, 2013. simulator code, benchmarks, slides (acceptance rate: 51/249 ≈ 20.5%) Selected for IEEE Micro Top Picks |
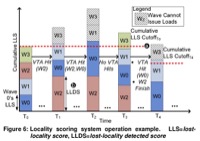 |
Timothy G. Rogers, Mike O'Connor, Tor M. Aamodt, Cache-Conscious Wavefront Scheduling, In proceedings of the 45th IEEE/ACM International Symposium on Microarchitecture (MICRO-45), pp. 72-83, Vancouver, BC, December 1-5, 2012. (acceptance rate: 40/228 ≈ 17.5%) Best paper runner up, Selected for IEEE Micro Top Picks, CACM Research Highlight, simulator code + benchmarks |
 |
Wilson W. L. Fung, Inderpreet Singh, Andrew Brownsword, Tor M. Aamodt, Kilo TM: Hardware Transactional Memory for GPU Architectures, IEEE Micro, Special Issue: Micro's Top Picks from 2011 Computer Architecture Conferences, Vol. 32, No. 3, pp. 7-16, May/June 2012. |
 |
Wilson W. L. Fung, Inderpreet Singh, Andrew Brownsword, Tor M. Aamodt, Hardware Transactional Memory for GPU Architectures, In proceedings of the 44th IEEE/ACM International Symposium on Microarchitecture (MICRO-44), pp. 296-307, Porto Alegre, Brazil, December 3-7, 2011. slides, longer talk, simulator as used in MICRO 2011 paper, simulator with recent changes to GPGPU-Sim 3.x, benchmarks (acceptance rate: 44/209 ≈ 21.0%) Selected for IEEE Micro Top Picks |
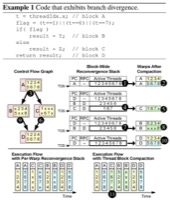 |
Wilson W. L. Fung, Tor M. Aamodt, Thread Block Compaction for Efficient SIMT Control Flow, In proceedings of the 17th IEEE International Symposium on High-Performance Computer Architecture (HPCA-17), pp. 25-36, San Antonio, Texas, February 12-16 2011. pre-print, slides, simulator code (acceptance rate: 42/227 ≈ 18.5%) |
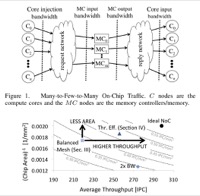 |
Ali Bakhoda, John Kim, Tor M. Aamodt, Throughput-Effective On-Chip Networks for Manycore Accelerators, In proceedings of the 43rd IEEE/ACM International Symposium on Microarchitecture (MICRO-43), pp. 421-432, Atlanta, Georgia, December 4-8, 2010. pre-print, BibTeX (acceptance rate: 45/248 ≈ 18.1%) |
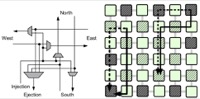 |
Ali Bakhoda, John Kim, Tor M. Aamodt, On-Chip Network Design Considerations for Compute Accelerators, In Nineteenth International Conference on Parallel Architectures and Compilation Techniques (PACT), pp. 535-536, Vienna, Austria, September 11-15, 2010. pre-print, BibTeX Best poster award, 2nd place |
 |
Aaron Ariel, Wilson W. L. Fung, Andrew Turner, Tor M. Aamodt, Visualizing Complex Dynamics in Many-Core Accelerator Architectures, In Proceedings of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pp. 164-174, White Plains, NY, March 28-30, 2010. pre-print, BibTeX (acceptance rate: 22/64 ≈ 34.4%) |
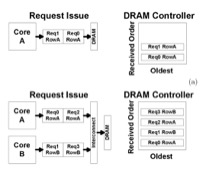 |
George L. Yuan, Ali Bakhoda, Tor M. Aamodt, Complexity Effective Memory Access Scheduling for Many-Core Accelerator Architectures, In proceedings of the 42nd IEEE/ACM International Symposium on Microarchitecture (MICRO-42), pp. 34-44, New York, NY, December 12-16, 2009. slides pre-print, BibTeX (acceptance rate: 52/209 ≈ 24.9%) |
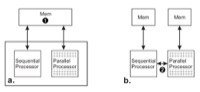 |
Henry Wong and Tor M. Aamodt, The Performance Potential for Single Application Heterogeneous Systems, 8th Annual Workshop on Duplicating, Deconstructing, and Debunking (WDDD 2009), (in conjunction with ISCA 2009), Austin, Texas, June 21, 2009. slides |
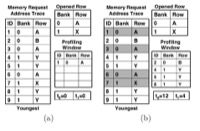 |
George L. Yuan and Tor M. Aamodt, A Hybrid Analytical DRAM Performance Model, 5th Workshop on Modeling, Benchmarking and Simulation (MoBS 2009), (in conjunction with ISCA 2009), Austin, Texas, June 21, 2009. |
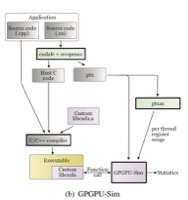 |
Ali Bakhoda, George L. Yuan, Wilson W. L. Fung, Henry Wong, Tor M. Aamodt, Analyzing CUDA Workloads Using a Detailed GPU Simulator, In proceedings of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pp. 163-174, Boston, MA, April 26-28, 2009. slides pre-print, simulator, BibTeX (acceptance rate: 24/86 ≈ 27.9%) |
 |
Henry Wong, Anne Bracy, Ethan Schuchman, Tor M. Aamodt, Jamison D. Collins, Perry H. Wang, Gautham Chinya, Ankur Khandelwal Groen, Hong Jiang, and Hong Wang, Pangaea: A Tightly-Coupled IA32 Heterogeneous Chip Multiprocessor, In proceedings of the 17th IEEE/ACM International Conference on Parallel Architectures and Compilation Techniques (PACT), pp. 52-61, Toronto, ON, October 25-29, 2008. pre-print, BibTeX (acceptance rate: 30/159 ≈ 18.9%) |
 |
Ali Bakhoda and Tor M. Aamodt, Extending the Scalability of Single Chip Stream Processors with On-chip Caches, 2nd Workshop on Chip Multiprocessor Memory Systems and Interconnects (CMP-MSI 2008), (in conjunction with ISCA 2008), 9 pages, Beijing, China, June 22, 2008. |
 |
Wilson W. L. Fung, Ivan Sham, George Yuan, and Tor M. Aamodt, Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow, In proceedings of the 40th IEEE/ACM International Symposium on Microarchitecture (MICRO-40), pp. 407-418, Chicago, IL, December 1-5, 2007. slides. pre-print, BibTeX (acceptance rate: 35/166 ≈ 21.1%) |