

COHESA: Computing Hardware for Emerging Intelligent Sensory Applications
COHESA was a large project exploring hardware for machine learning. It was a $5 million NSERC strategic network involving about twenty faculty members at several universities across Canada that wrapped up in late 2023. Several of the graduate students in my group were involved in research related to COHESA.
COHESA was motivated by the combination of slowing advances in semiconductor technology combined with recent rapid progress in the use of machine learning to increase automation. These two trends have led to development of use of general purpose accelerators such as GPUs along with development of special purpose accelerators such as Google's Tensor Processing Unit and numerous chip start ups.
Previously, students in my group explored how to accelerate deep networks by exploring redundancy during inference. You can find details of this work in the publications listed below. We are now exploring how to accelerate machine learning by studying redundancy during training. We are following a hardware/software co-design approach that involves understanding both the machine learning training algorithms as well as hardware implementation technology. As most training of neural networks is performed today on GPUs, we are updating our simulator, GPGPU-Sim to model recent GPU architectures such as NVIDIA's Volta and to support software libraries such as cuDNN. We are also studying application specific accelerators for training of neural networks.
Past supporting organizations:






Publications
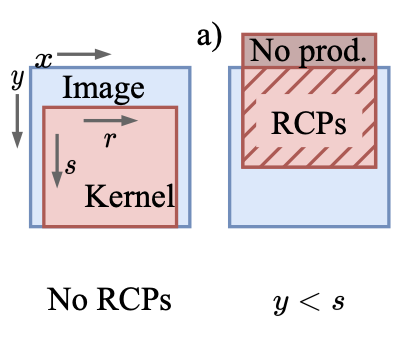 |
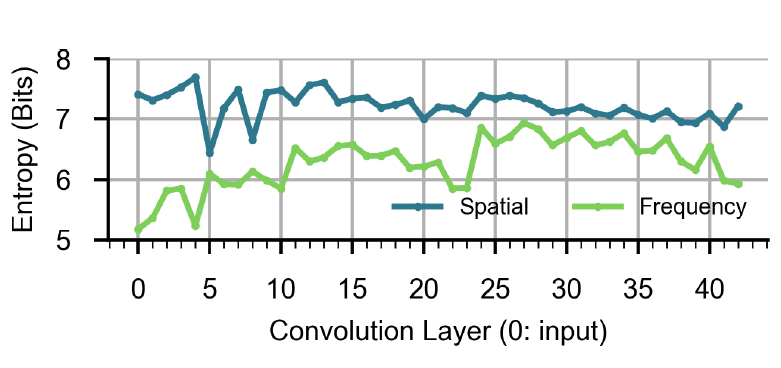
Jonathan Lew, Yunpeng Liu, Wenyi Gong, Negar Goli, R. David Evans, Tor M. Aamodt, Anticipating and Eliminating Redundant Computations in Accelerated Sparse Training, In proceedings of the IEEE/ACM International Symposium on Computer Architecture (ISCA 2022), New York City, New York, USA, June 11–15, 2022. (acceptance rate: 67/400 ≈ 17%) |
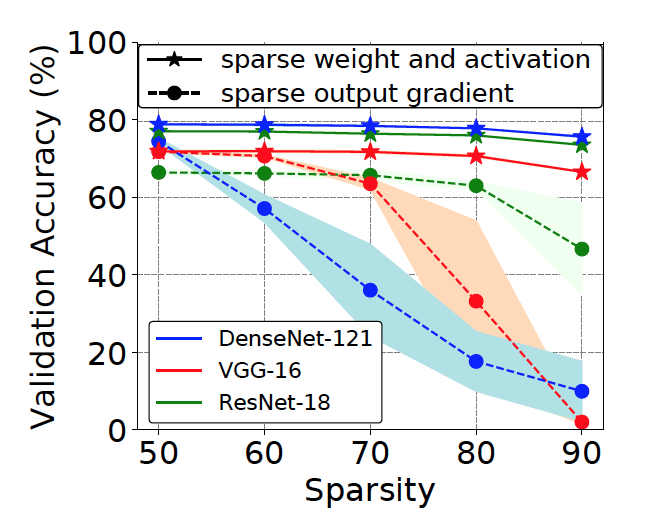 |
Md Aamir Raihan, Tor M. Aamodt, Sparse Weight Activation Training, In proceedings of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS 2020), Virtual-only Conference, Dec 6-12, 2020. (acceptance rate: 1900/9454 ≈ 20.1%) |
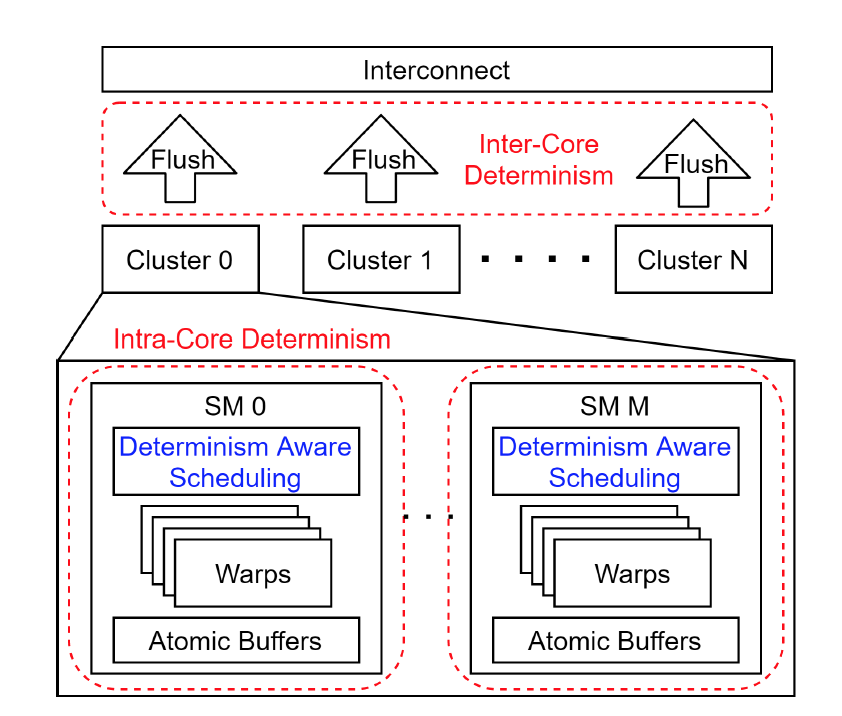 |
Yuan Hsi Chou, Christopher Ng, Shaylin Cattell, Jeremy Intan, Matthew D. Sinclair, Joseph Devietti, Timothy G. Rogers, Tor M. Aamodt, Deterministic Atomic Buffering, In proceedings of the 53rd IEEE/ACM International Symposium on Microarchitecture (MICRO), October 17-21, 2020 Athens, Greece. (acceptance rate: 82/422 ≈ 19.4%) Videos: Full talk, Lightning talk |
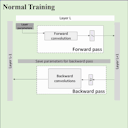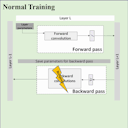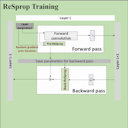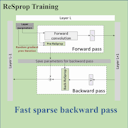 |
Negar Goli, Tor M. Aamodt, ReSprop: Reuse Sparsified Backpropagation, In proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, June 16-18, 2020. (Oral presentation) Video of Negar's CVPR Talk |
 |
R. David Evans, Lufei Liu, Tor M. Aamodt, JPEG-ACT: Accelerating Deep Learning via Transform-based Lossy Compression, In proceedings of the 2020 IEEE/ACM International Symposium on Computer Architecture (ISCA), Valencia, Spain, May 30-June 3, 2020. Video of Dave's ISCA Talk |
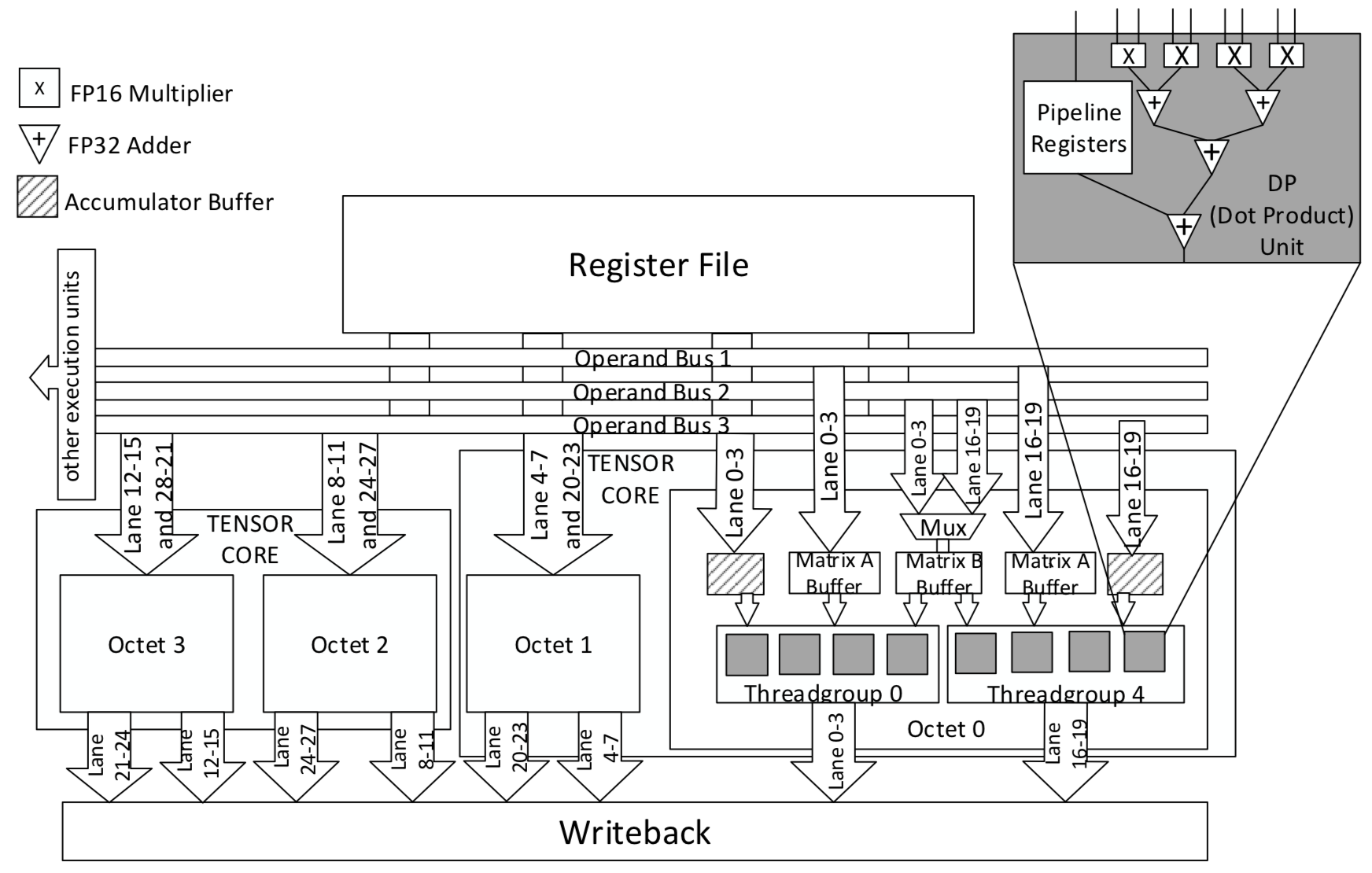 |
Md Aamir Raihan, Negar Goli, Tor M. Aamodt, Modeling Deep Learning Accelerator Enabled GPUs, In proceedings of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pp. 79-92, Madison, Wisconsin, March 24-26, 2019. |
 |
Andreas Moshovos, Jorge Albericio, Patrick Judd, Alberto Delmas Lascorz, Sayeh Sharify, Zissis Poulos, Tayler Hetherington, Tor Aamodt, Natalie Enright Jerger, Exploiting Typical Values to Accelerate Deep Learning, IEEE Computer, Volume 51, Issue 5, May 2018. |
 |
Andreas Moshovos, Jorge Albericio, Patrick Judd, Alberto Delmas Lascorz, Sayeh Sharify, Tayler Hetherington, Tor Aamodt, Natalie Enright Jerger, Value-Based Deep-Learning Acceleration, IEEE Micro, Volume 38, Issue 1, January/February 2018. |
 |
Patrick Judd, Jorge Albericio, Tayler Hetherington, Tor Aamodt, Natalie Enright Jerger, Raquel Urtasun, Andreas Moshovos, Proteus: Exploiting Precision Variability in Deep Neural Networks, Parallel Computing, Volume 73, April 2018. |
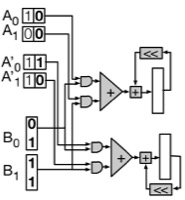 |
Patrick Judd, Jorge Albericio, Tayler Hetherington, Tor M. Aamodt, Andreas Moshovos, Stripes: Bit-Serial Deep Neural Network Computing, in proceedings of the ACM/IEEE Int'l Symposium on Microarchitecture (MICRO'16), Taipei, Taiwan, Oct. 15-19, 2016. (acceptance rate: 61/288 ≈ 21.2%) IEEE Micro Top Picks "Honorable Mention" |
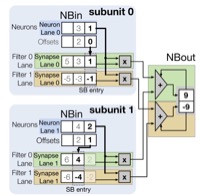 |
Jorge Albericio, Patrick Judd, Tayler Hetherington, Tor Aamodt, Natalie Enright Jerger, Andreas Moshovos, Cnvlutin: Ineffectual-Neuron-Free Deep Convolutional Neural Network Computing, in proceedings of the ACM/IEEE Int'l Symposium on Computer Architecture (ISCA'16), Seoul, Korea, June 18-22 2016. (acceptance rate: 54/288 ≈ 18.8%) |
 |
Patrick Judd, Jorge Albericio, Tayler Hetherington, Tor Aamodt, Natalie Enright Jerger, Andreas Moshovos, Proteus: Exploiting Numerical Precision Variability in Deep Neural Networks, in proceedings of the ACM International Conference on Supercomputing (ICS 2016), Istanbul, Turkey, June 1-3, 2016. (acceptance rate: 43/183 ≈ 23.5%) |