We will now examine how block transfers can be performed in the multiprocessor. Remote-to-local block transfers are performed in the base system using a sequence of read and write commands. Each read command causes a single word to be transferred from the remote memory to one of the processor's registers and is followed by a write command which writes the received word into the processor's local memory. Each read that misses in the cache causes a read request to be sent through the network. The writes are all local writes; they do not cause any interprocessor traffic.
Now consider an ``enhanced'' multiprocessor in which the operating system (or the user program) can transfer a block from a remote memory to the local memory using the single instruction:
![]()
Figure  shows the new node interface.
A new queue (
shows the new node interface.
A new queue ( ![]() ), large enough
to contain the largest block of data that will be
transferred, has been added.
Also, queue
), large enough
to contain the largest block of data that will be
transferred, has been added.
Also, queue ![]() has been made large enough to contain an entire
block.
has been made large enough to contain an entire
block.
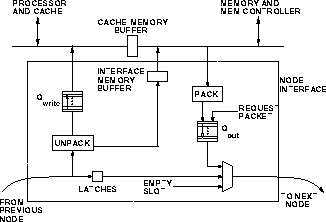
Figure: Enhanced node architecture
Consider what happens when the processor executes a block transfer
instruction in the enhanced multiprocessor.
First, the processor signals the local node interface that
a block transfer is to occur, and transfers the
source and destination address
to the node interface. A request packet, called a
block read request, is constructed and
stored in ![]() .
The first empty slot on the ring will be filled with
the request packet.
.
The first empty slot on the ring will be filled with
the request packet.
When the remote node interface receives the request
(and accepts it),
it reads the entire
block from memory.
We will refer to this as the read phase.
Upon reading data from its memory, the remote node interface constructs
data return packets and stores them in ![]() . Eight bytes of
data can be packed into each packet. When an empty slot appears on the ring,
the top entry in
. Eight bytes of
data can be packed into each packet. When an empty slot appears on the ring,
the top entry in ![]() is returned to the requesting
node. The packing and transmission of packets is called the transfer
phase. If the network is heavily utilized, it is possible that much (or
all) of the block will be read from memory before it is sent; queue
is returned to the requesting
node. The packing and transmission of packets is called the transfer
phase. If the network is heavily utilized, it is possible that much (or
all) of the block will be read from memory before it is sent; queue
![]() must therefore be large enough to contain an entire block.
must therefore be large enough to contain an entire block.
When the requesting node interface receives the data packets, it writes
the data directly to the local memory through the
cache-memory buffer. This is the write phase. If the
data arrives on the network faster that it can be stored in memory, queue
![]() will hold the overflow. Thus,
will hold the overflow. Thus, ![]() should also be large enough to contain an entire block.
Once the write phase has been completed, the node interface
signals the processor that it can continue.
should also be large enough to contain an entire block.
Once the write phase has been completed, the node interface
signals the processor that it can continue.
Note that the data being written during the write phase goes through the cache-memory buffer. All other requests, including read requests originating from another node, go through the interface-memory buffer. Consider a node in the write phase of its own block transfer. If an unrelated request from another node arrives, the new request can be accepted, since the path through the node interface-memory buffer is not being used by the block write. The round-robin scheduling of requests in the two memory buffers described earlier would result in the memory bandwidth being shared between the block write and the new request. Note that this is only possible because we have assumed that the processor will not issue a new request until the previous request has been satisfied. During a block write, we are guaranteed that the cache will not issue a new request and therefore will not use the cache-memory buffer.
It is intuitive that such a system would perform block transfers much faster than the base architecture; not only is less time wasted transferring individual request messages, but also if many processors are trying to access the same memory, this new ``enhanced'' architecture will only have to compete once to transfer a page, while the base architecture will have to compete for each word (or cache line).