ConvolutionTransformation transformation¶
ngraph::pass::low_precision::ConvolutionTransformation class represents the Convolution operation transformation.
The transformation propagates dequantization operations on activations and weights through the Convolution operation. The transformation supports several weights quantization approaches:
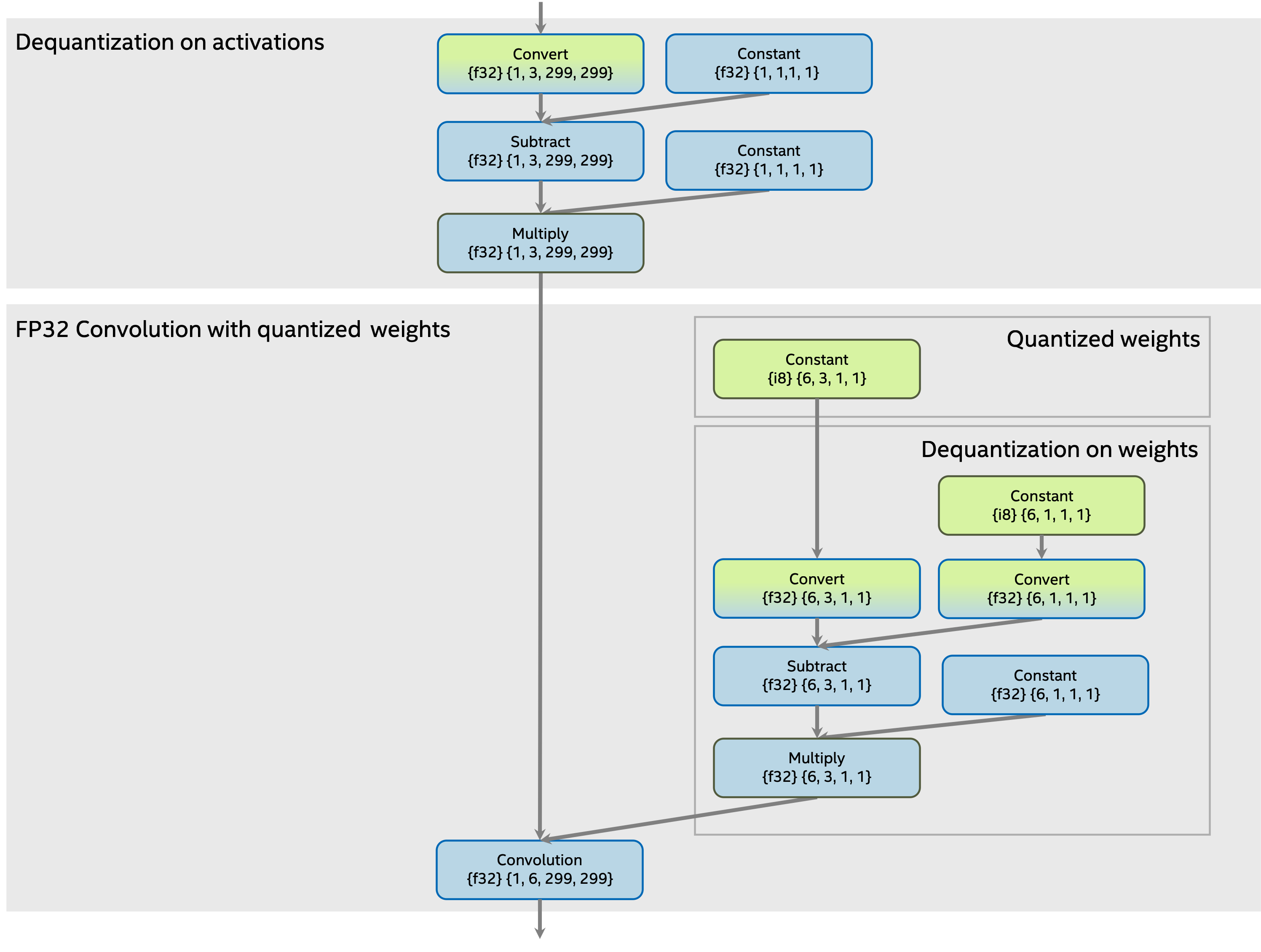
quantized weights in low precision with dequantization operations,
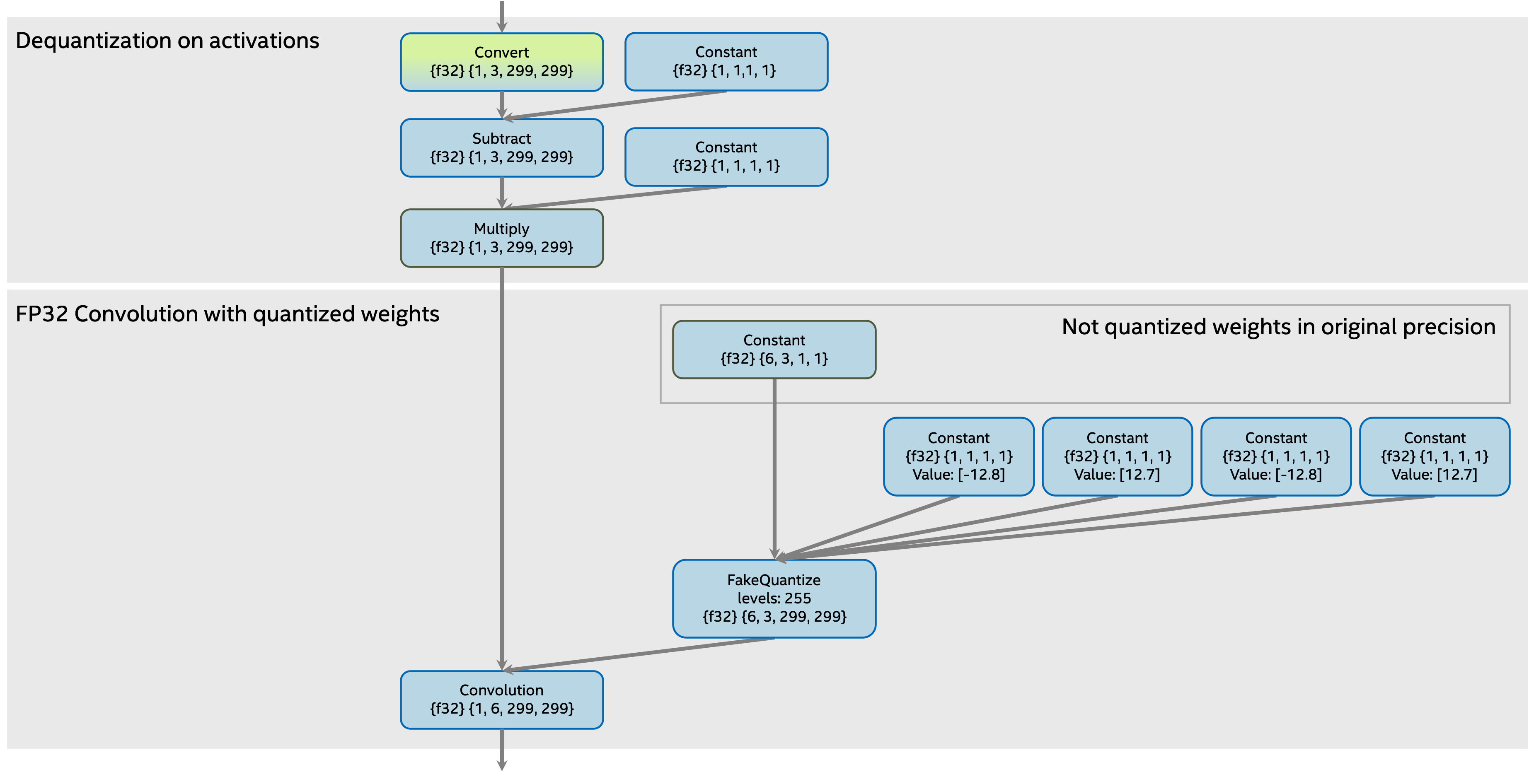
weights in original precision with
FakeQuantizeoperation.
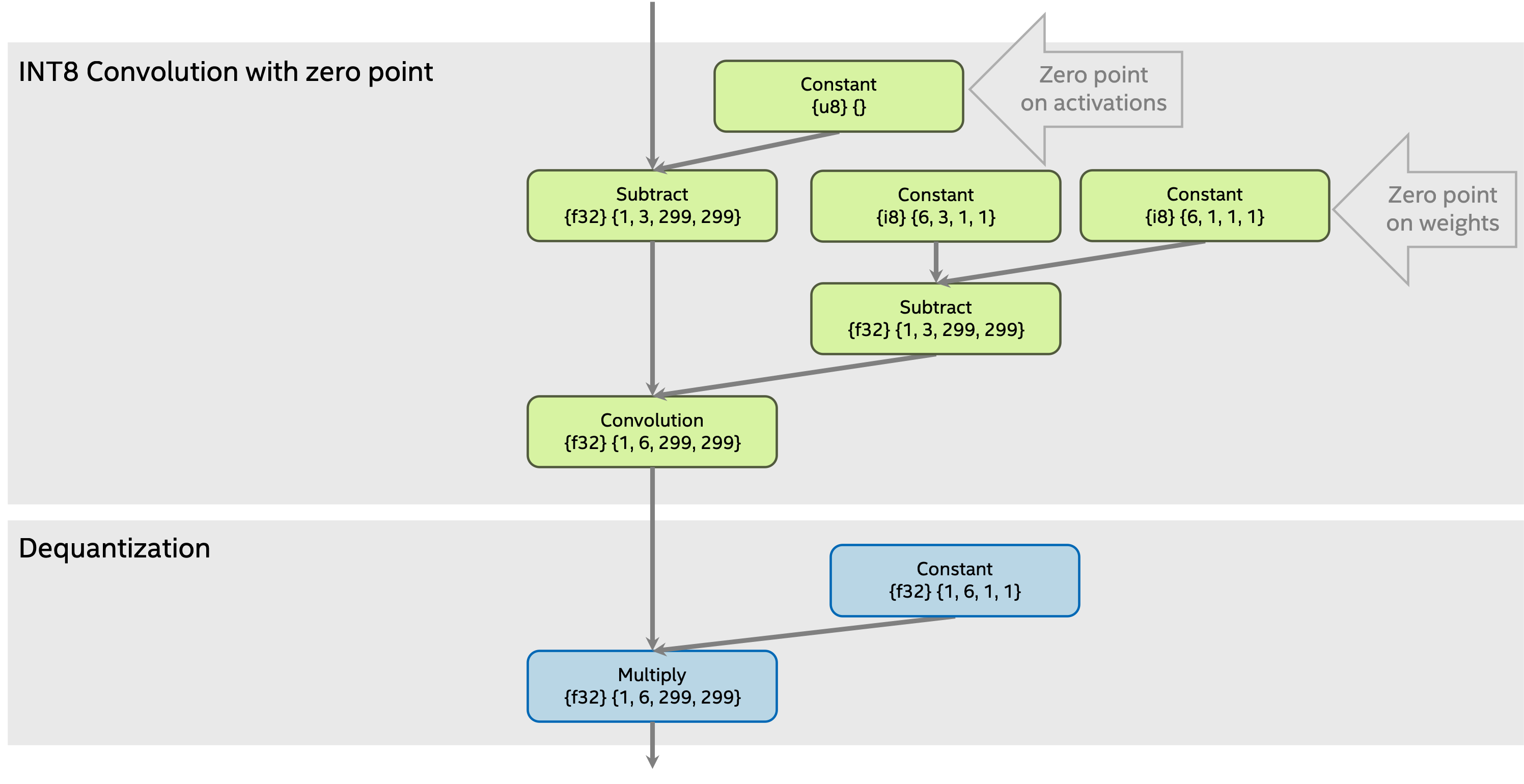
Result dequantization Multiply constant value result is calculated as multiplication for dequantization Multiply constant value on activations a and dequantization Multiply constant value on weights b :
Limitations¶
Dequantization on activations must be per-tensor. It means that dequantization
Multiplyconstant value on activations must be scalar.
Subgraph before transformation¶
Quantized weights in low precision with dequantization operations¶
The subgraph with quantized Convolution before transformation with quantized weights in low precision constant and dequantization operations:
Weights in original precision with FakeQuantize operation¶
The subgraph with quantized Convolution before transformation with weights in original precision and FakeQuantize operation: