4.4 Quality Attribute Scenarios in Practice
General scenarios provide a framework for generating a large number of generic, system-independent, quality-attribute-specific scenarios. Each is potentially but not necessarily relevant to the system you are concerned with. To make the general scenarios useful for a particular system, you must make them system specific.
Making a general scenario system specific means translating it into concrete terms for the particular system. Thus, a general scenario is "A request arrives for a change in functionality, and the change must be made at a particular time within the development process within a specified period." A system-specific version might be "A request arrives to add support for a new browser to a Web-based system, and the change must be made within two weeks." Furthermore, a single general scenario may have many system-specific versions. The same system that has to support a new browser may also have to support a new media type.
We now discuss the six most common and important system quality attributes, with the twin goals of identifying the concepts used by the attribute community and providing a way to generate general scenarios for that attribute.
AVAILABILITY
Availability is concerned with system failure and its associated consequences. A system failure occurs when the system no longer delivers a service consistent with its specification. Such a failure is observable by the system's users-either humans or other systems. An example of an availability general scenario appeared in Figure 4.3.
Among the areas of concern are how system failure is detected, how frequently system failure may occur, what happens when a failure occurs, how long a system is allowed to be out of operation, when failures may occur safely, how failures can be prevented, and what kinds of notifications are required when a failure occurs.
We need to differentiate between failures and faults. A fault may become a failure if not corrected or masked. That is, a failure is observable by the system's user and a fault is not. When a fault does become observable, it becomes a failure. For example, a fault can be choosing the wrong algorithm for a computation, resulting in a miscalculation that causes the system to fail.
Once a system fails, an important related concept becomes the time it takes to repair it. Since a system failure is observable by users, the time to repair is the time until the failure is no longer observable. This may be a brief delay in the response time or it may be the time it takes someone to fly to a remote location in the mountains of Peru to repair a piece of mining machinery (this example was given by a person who was responsible for repairing the software in a mining machine engine.).
The distinction between faults and failures allows discussion of automatic repair strategies. That is, if code containing a fault is executed but the system is able to recover from the fault without it being observable, there is no failure.
The availability of a system is the probability that it will be operational when it is needed. This is typically defined as
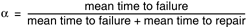
From this come terms like 99.9% availability, or a 0.1% probability that the system will not be operational when needed.
Scheduled downtimes (i.e., out of service) are not usually considered when calculating availability, since the system is "not needed" by definition. This leads to situations where the system is down and users are waiting for it, but the downtime is scheduled and so is not counted against any availability requirements.
Availability General Scenarios
From these considerations we can see the portions of an availability scenario, shown in Figure 4.2.
Source of stimulus.
We differentiate between internal and external indications of faults or failure since the desired system response may be different. In our example, the unexpected message arrives from outside the system.
Stimulus.
A fault of one of the following classes occurs.
- - omission.
A component fails to respond to an input.
- - crash.
The component repeatedly suffers omission faults.
- - timing.
A component responds but the response is early or late.
- - response.
A component responds with an incorrect value.
- In Figure 4.3, the stimulus is that an unanticipated message arrives. This is an example of a timing fault. The component that generated the message did so at a different time than expected. Artifact.
This specifies the resource that is required to be highly available, such as a processor, communication channel, process, or storage.
Environment.
The state of the system when the fault or failure occurs may also affect the desired system response. For example, if the system has already seen some faults and is operating in other than normal mode, it may be desirable to shut it down totally. However, if this is the first fault observed, some degradation of response time or function may be preferred. In our example, the system is operating normally.
Response.
There are a number of possible reactions to a system failure. These include logging the failure, notifying selected users or other systems, switching to a degraded mode with either less capacity or less function, shutting down external systems, or becoming unavailable during repair. In our example, the system should notify the operator of the unexpected message and continue to operate normally.
Response measure.
The response measure can specify an availability percentage, or it can specify a time to repair, times during which the system must be available, or the duration for which the system must be available. In Figure 4.3, there is no downtime as a result of the unexpected message.
Table 4.1 presents the possible values for each portion of an availability scenario.
Table 4.1. Availability General Scenario Generation
|
Source
|
Internal to the system; external to the system
|
|
Stimulus
|
Fault:
omission, crash, timing, response
|
|
Artifact
|
System's processors, communication channels, persistent storage, processes
|
|
Environment
|
Normal operation;
degraded mode (i.e., fewer features, a fall back solution)
|
|
Response
|
System should detect event and do one or more of the following:
record it
notify appropriate parties, including the user and other systems
disable sources of events that cause fault or failure according to defined rules
be unavailable for a prespecified interval, where interval depends on criticality of system
continue to operate in normal or degraded mode
|
|
Response Measure
|
Time interval when the system must be available
Availability time
Time interval in which system can be in degraded mode
Repair time
|
MODIFIABILITY
Modifiability is about the cost of change. It brings up two concerns.
What can change (the artifact)? A change can occur to any aspect of a system, most commonly the functions that the system computes, the platform the system exists on (the hardware, operating system, middleware, etc.), the environment within which the system operates (the systems with which it must interoperate, the protocols it uses to communicate with the rest of the world, etc.), the qualities the system exhibits (its performance, its reliability, and even its future modifications), and its capacity (number of users supported, number of simultaneous operations, etc.). Some portions of the system, such as the user interface or the platform, are sufficiently distinguished and subject to change that we consider them separately. The category of platform changes is also called portability. Those changes may be to add, delete, or modify any one of these aspects. When is the change made and who makes it (the environment)?
Most commonly in the past, a change was made to source code. That is, a developer had to make the change, which was tested and then deployed in a new release. Now, however, the question of when a change is made is intertwined with the question of who makes it. An end user changing the screen saver is clearly making a change to one of the aspects of the system. Equally clear, it is not in the same category as changing the system so that it can be used over the Web rather than on a single machine. Changes can be made to the implementation (by modifying the source code), during compile (using compile-time switches), during build (by choice of libraries), during configuration setup (by a range of techniques, including parameter setting) or during execution (by parameter setting). A change can also be made by a developer, an end user, or a system administrator.
Once a change has been specified, the new implementation must be designed, implemented, tested, and deployed. All of these actions take time and money, both of which can be measured.
Modifiability General Scenarios
From these considerations we can see the portions of the modifiability general scenarios. Figure 4.4 gives an example: "A developer wishes to change the user interface. This change will be made to the code at design time, it will take less than three hours to make and test the change, and no side-effect changes will occur in the behavior."
Source of stimulus.
This portion specifies who makes the changes-the developer, a system administrator, or an end user. Clearly, there must be machinery in place to allow the system administrator or end user to modify a system, but this is a common occurrence. In Figure 4.4, the modification is to be made by the developer.
Stimulus.
This portion specifies the changes to be made. A change can be the addition of a function, the modification of an existing function, or the deletion of a function. It can also be made to the qualities of the system-making it more responsive, increasing its availability, and so forth. The capacity of the system may also change. Increasing the number of simultaneous users is a frequent requirement. In our example, the stimulus is a request to make a modification, which can be to the function, quality, or capacity.
Variation is a concept associated with software product lines (see Chapter 14). When considering variation, a factor is the number of times a given variation must be specified. One that must be made frequently will impose a more stringent requirement on the response measures than one that is made only sporadically. Artifact.
This portion specifies what is to be changed-the functionality of a system, its platform, its user interface, its environment, or another system with which it interoperates. In Figure 4.4, the modification is to the user interface.
Environment.
This portion specifies when the change can be made-design time, compile time, build time, initiation time, or runtime. In our example, the modification is to occur at design time.
Response.
Whoever makes the change must understand how to make it, and then make it, test it and deploy it. In our example, the modification is made with no side effects.
Response measure.
All of the possible responses take time and cost money, and so time and cost are the most desirable measures. Time is not always possible to predict, however, and so less ideal measures are frequently used, such as the extent of the change (number of modules affected). In our example, the time to perform the modification should be less than three hours.
Table 4.2 presents the possible values for each portion of a modifiability scenario.
Table 4.2. Modifiability General Scenario Generation
|
Source
|
End user, developer, system administrator
|
|
Stimulus
|
Wishes to add/delete/modify/vary functionality, quality attribute, capacity
|
|
Artifact
|
System user interface, platform, environment; system that interoperates with target system
|
|
Environment
|
At runtime, compile time, build time, design time
|
|
Response
|
Locates places in architecture to be modified; makes modification without affecting other functionality; tests modification; deploys modification
|
|
Response Measure
|
Cost in terms of number of elements affected, effort, money; extent to which this affects other functions or quality attributes
|
PERFORMANCE
Performance is about timing. Events (interrupts, messages, requests from users, or the passage of time) occur, and the system must respond to them. There are a variety of characterizations of event arrival and the response but basically performance is concerned with how long it takes the system to respond when an event occurs.
One of the things that make performance complicated is the number of event sources and arrival patterns. Events can arrive from user requests, from other systems, or from within the system. A Web-based financial services system gets events from its users (possibly numbering in the tens or hundreds of thousands). An engine control system gets its requests from the passage of time and must control both the firing of the ignition when a cylinder is in the correct position and the mixture of the fuel to maximize power and minimize pollution.
For the Web-based financial system, the response might be the number of transactions that can be processed in a minute. For the engine control system, the response might be the variation in the firing time. In each case, the pattern of events arriving and the pattern of responses can be characterized, and this characterization forms the language with which to construct general performance scenarios.
A performance scenario begins with a request for some service arriving at the system. Satisfying the request requires resources to be consumed. While this is happening the system may be simultaneously servicing other requests.
An arrival pattern for events may be characterized as either periodic or stochastic. For example, a periodic event may arrive every 10 milliseconds. Periodic event arrival is most often seen in real-time systems. Stochastic arrival means that events arrive according to some probabilistic distribution. Events can also arrive sporadically, that is, according to a pattern not capturable by either periodic or stochastic characterizations.
Multiple users or other loading factors can be modeled by varying the arrival pattern for events. In other words, from the point of view of system performance, it does not matter whether one user submits 20 requests in a period of time or whether two users each submit 10. What matters is the arrival pattern at the server and dependencies within the requests.
The response of the system to a stimulus can be characterized by latency (the time between the arrival of the stimulus and the system's response to it), deadlines in processing (in the engine controller, for example, the fuel should ignite when the cylinder is in a particular position, thus introducing a processing deadline), the throughput of the system (e.g., the number of transactions the system can process in a second), the jitter of the response (the variation in latency), the number of events not processed because the system was too busy to respond, and the data that was lost because the system was too busy.
Notice that this formulation does not consider whether the system is networked or standalone. Nor does it (yet) consider the configuration of the system or the consumption of resources. These issues are dependent on architectural solutions, which we will discuss in Chapter 5.
Performance General Scenarios
From these considerations we can see the portions of the performance general scenario, an example of which is shown in Figure 4.5: "Users initiate 1,000 transactions per minute stochastically under normal operations, and these transactions are processed with an average latency of two seconds."
Source of stimulus.
The stimuli arrive either from external (possibly multiple) or internal sources. In our example, the source of the stimulus is a collection of users.
Stimulus.
The stimuli are the event arrivals. The arrival pattern can be characterized as periodic, stochastic, or sporadic. In our example, the stimulus is the stochastic initiation of 1,000 transactions per minute.
Artifact.
The artifact is always the system's services, as it is in our example.
Environment.
The system can be in various operational modes, such as normal, emergency, or overload. In our example, the system is in normal mode.
Response.
The system must process the arriving events. This may cause a change in the system environment (e.g., from normal to overload mode). In our example, the transactions are processed.
Response measure.
The response measures are the time it takes to process the arriving events (latency or a deadline by which the event must be processed), the variation in this time (jitter), the number of events that can be processed within a particular time interval (throughput), or a characterization of the events that cannot be processed (miss rate, data loss). In our example, the transactions should be processed with an average latency of two seconds.
Table 4.3 gives elements of the general scenarios that characterize performance.
Table 4.3. Performance General Scenario Generation
|
Source
|
One of a number of independent sources, possibly from within system
|
|
Stimulus
|
Periodic events arrive; sporadic events arrive; stochastic events arrive
|
|
Artifact
|
System
|
|
Environment
|
Normal mode; overload mode
|
|
Response
|
Processes stimuli; changes level of service
|
|
Response Measure
|
Latency, deadline, throughput, jitter, miss rate, data loss
|
For most of the history of software engineering, performance has been the driving factor in system architecture. As such, it has frequently compromised the achievement of all other qualities. As the price/performance ratio of hardware plummets and the cost of developing software rises, other qualities have emerged as important competitors to performance.
SECURITY
Security is a measure of the system's ability to resist unauthorized usage while still providing its services to legitimate users. An attempt to breach security is called an attack and can take a number of forms. It may be an unauthorized attempt to access data or services or to modify data, or it may be intended to deny services to legitimate users.
Attacks, often occasions for wide media coverage, may range from theft of money by electronic transfer to modification of sensitive data, from theft of credit card numbers to destruction of files on computer systems, or to denial-of-service attacks carried out by worms or viruses. Still, the elements of a security general scenario are the same as the elements of our other general scenarios-a stimulus and its source, an environment, the target under attack, the desired response of the system, and the measure of this response.
Security can be characterized as a system providing nonrepudiation, confidentiality, integrity, assurance, availability, and auditing. For each term, we provide a definition and an example.
Nonrepudiation is the property that a transaction (access to or modification of data or services) cannot be denied by any of the parties to it. This means you cannot deny that you ordered that item over the Internet if, in fact, you did. Confidentiality is the property that data or services are protected from unauthorized access. This means that a hacker cannot access your income tax returns on a government computer. Integrity is the property that data or services are being delivered as intended. This means that your grade has not been changed since your instructor assigned it. Assurance is the property that the parties to a transaction are who they purport to be. This means that, when a customer sends a credit card number to an Internet merchant, the merchant is who the customer thinks they are. Availability is the property that the system will be available for legitimate use. This means that a denial-of-service attack won't prevent your ordering this book. Auditing is the property that the system tracks activities within it at levels sufficient to reconstruct them. This means that, if you transfer money out of one account to another account, in Switzerland, the system will maintain a record of that transfer.
Each of these security categories gives rise to a collection of general scenarios.
Security General Scenarios
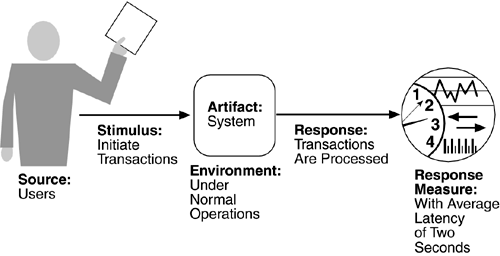
The portions of a security general scenario are given below. Figure 4.6 presents an example. A correctly identified individual tries to modify system data from an external site; system maintains an audit trail and the correct data is restored within one day.
Source of stimulus.
The source of the attack may be either a human or another system. It may have been previously identified (either correctly or incorrectly) or may be currently unknown. If the source of the attack is highly motivated (say politically motivated), then defensive measures such as "We know who you are and will prosecute you" are not likely to be effective; in such cases the motivation of the user may be important. If the source has access to vast resources (such as a government), then defensive measures are very difficult. The attack itself is unauthorized access, modification, or denial of service.
The difficulty with security is allowing access to legitimate users and determining legitimacy. If the only goal were to prevent access to a system, disallowing all access would be an effective defensive measure. 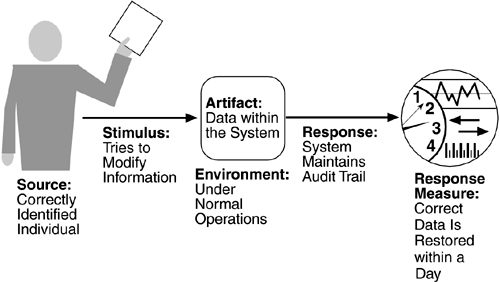
Stimulus.
The stimulus is an attack or an attempt to break security. We characterize this as an unauthorized person or system trying to display information, change and/or delete information, access services of the system, or reduce availability of system services. In Figure 4.6, the stimulus is an attempt to modify data.
Artifact.
The target of the attack can be either the services of the system or the data within it. In our example, the target is data within the system.
Environment.
The attack can come when the system is either online or offline, either connected to or disconnected from a network, either behind a firewall or open to the network.
Response.
Using services without authorization or preventing legitimate users from using services is a different goal from seeing sensitive data or modifying it. Thus, the system must authorize legitimate users and grant them access to data and services, at the same time rejecting unauthorized users, denying them access, and reporting unauthorized access. Not only does the system need to provide access to legitimate users, but it needs to support the granting or withdrawing of access. One technique to prevent attacks is to cause fear of punishment by maintaining an audit trail of modifications or attempted accesses. An audit trail is also useful in correcting from a successful attack. In Figure 4.6, an audit trail is maintained.
Response measure.
Measures of a system's response include the difficulty of mounting various attacks and the difficulty of recovering from and surviving attacks. In our example, the audit trail allows the accounts from which money was embezzled to be restored to their original state. Of course, the embezzler still has the money, and he must be tracked down and the money regained, but this is outside of the realm of the computer system.
Table 4.4 shows the security general scenario generation table.
Table 4.4. Security General Scenario Generation
|
Source
|
Individual or system that is
correctly identified, identified incorrectly, of unknown identity
who is
internal/external, authorized/not authorized
with access to
limited resources, vast resources
|
|
Stimulus
|
Tries to
display data, change/delete data, access system services, reduce availability to system services
|
|
Artifact
|
System services; data within system
|
|
Environment
|
Either
online or offline, connected or disconnected, firewalled or open
|
|
Response
|
Authenticates user; hides identity of the user; blocks access to data and/or services; allows access to data and/or services; grants or withdraws permission to access data and/or services; records access/modifications or attempts to access/modify data/services by identity; stores data in an unreadable format; recognizes an unexplainable high demand for services, and informs a user or another system, and restricts availability of services
|
|
Response Measure
|
Time/effort/resources required to circumvent security measures with probability of success; probability of detecting attack; probability of identifying individual responsible for attack or access/modification of data and/or services; percentage of services still available under denial-of-services attack; restore data/services; extent to which data/services damaged and/or legitimate access denied
|
TESTABILITY
Software testability refers to the ease with which software can be made to demonstrate its faults through (typically execution-based) testing. At least 40% of the cost of developing well-engineered systems is taken up by testing. If the software architect can reduce this cost, the payoff is large.
In particular, testability refers to the probability, assuming that the software has at least one fault, that it will fail on its next test execution. Of course, calculating this probability is not easy and, when we get to response measures, other measures will be used.
For a system to be properly testable, it must be possible to control each component's internal state and inputs and then to observe its outputs. Frequently this is done through use of a test harness, specialized software designed to exercise the software under test. This may be as simple as a playback capability for data recorded across various interfaces or as complicated as a testing chamber for an engine.
Testing is done by various developers, testers, verifiers, or users and is the last step of various parts of the software life cycle. Portions of the code, the design, or the complete system may be tested. The response measures for testability deal with how effective the tests are in discovering faults and how long it takes to perform the tests to some desired level of coverage.
Testability General Scenarios
Figure 4.7 is an example of a testability scenario concerning the performance of a unit test: A unit tester performs a unit test on a completed system component that provides an interface for controlling its behavior and observing its output; 85% path coverage is achieved within three hours.
Source of stimulus.
The testing is performed by unit testers, integration testers, system testers, or the client. A test of the design may be performed by other developers or by an external group. In our example, the testing is performed by a tester.
Stimulus.
The stimulus for the testing is that a milestone in the development process is met. This might be the completion of an analysis or design increment, the completion of a coding increment such as a class, the completed integration of a subsystem, or the completion of the whole system. In our example, the testing is triggered by the completion of a unit of code.
Artifact.
A design, a piece of code, or the whole system is the artifact being tested. In our example, a unit of code is to be tested.
Environment.
The test can happen at design time, at development time, at compile time, or at deployment time. In Figure 4.7, the test occurs during development.
Response.
Since testability is related to observability and controllability, the desired response is that the system can be controlled to perform the desired tests and that the response to each test can be observed. In our example, the unit can be controlled and its responses captured.
Response measure.
Response measures are the percentage of statements that have been executed in some test, the length of the longest test chain (a measure of the difficulty of performing the tests), and estimates of the probability of finding additional faults. In Figure 4.7, the measurement is percentage coverage of executable statements.
Table 4.5 gives the testability general scenario generation table.
Table 4.5. Testability General Scenario Generation
|
Source
|
Unit developer
Increment integrator
System verifier
Client acceptance tester
System user
|
|
Stimulus
|
Analysis, architecture, design, class, subsystem integration completed; system delivered
|
|
Artifact
|
Piece of design, piece of code, complete application
|
|
Environment
|
At design time, at development time, at compile time, at deployment time
|
|
Response
|
Provides access to state values; provides computed values; prepares test environment
|
|
Response Measure
|
Percent executable statements executed
Probability of failure if fault exists
Time to perform tests
Length of longest dependency chain in a test
Length of time to prepare test environment
|
USABILITY
Usability is concerned with how easy it is for the user to accomplish a desired task and the kind of user support the system provides. It can be broken down into the following areas:
Learning system features.
If the user is unfamiliar with a particular system or a particular aspect of it, what can the system do to make the task of learning easier?
Using a system efficiently.
What can the system do to make the user more efficient in its operation?
Minimizing the impact of errors.
What can the system do so that a user error has minimal impact?
Adapting the system to user needs.
How can the user (or the system itself) adapt to make the user's task easier?
Increasing confidence and satisfaction.
What does the system do to give the user confidence that the correct action is being taken?
In the last five years, our understanding of the relation between usability and software architecture has deepened (see the sidebar Usability Mea Culpa). The normal development process detects usability problems through building prototypes and user testing. The later a problem is discovered and the deeper into the architecture its repair must be made, the more the repair is threatened by time and budget pressures. In our scenarios we focus on aspects of usability that have a major impact on the architecture. Consequently, these scenarios must be correct prior to the architectural design so that they will not be discovered during user testing or prototyping.
Usability General Scenarios
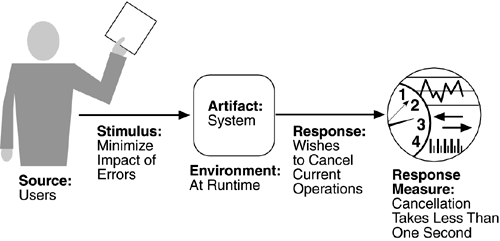
Figure 4.8 gives an example of a usability scenario: A user, wanting to minimize the impact of an error, wishes to cancel a system operation at runtime; cancellation takes place in less than one second. The portions of the usability general scenarios are:
Source of stimulus.
The end user is always the source of the stimulus.
Stimulus.
The stimulus is that the end user wishes to use a system efficiently, learn to use the system, minimize the impact of errors, adapt the system, or feel comfortable with the system. In our example, the user wishes to cancel an operation, which is an example of minimizing the impact of errors.
Artifact.
The artifact is always the system.
|
About five years ago a number of respected software engineering researchers publicly made the following bold statement:
Making a system's user interface clear and easy to use is primarily a matter of getting the details of a user's interaction correct … but these details are not architectural.
Sad to say, these researchers were Bass, Clements, and Kazman, and the book was the first edition of Software Architecture in Practice. In the intervening five years we have learned quite a lot about many quality attributes, and none more so than usability.
While we have always claimed that system quality stems primarily from architectural quality, in the first edition of this book we were, at times, on shaky ground in trying to substantiate this claim. Still, the intervening years have done nothing to lessen the basic truth of the strong relationship between architectural quality and system quality. In fact, all of the evidence points squarely in its favor, and usability has proven to be no exception. Many usability issues are architectural. In fact, the usability features that are the most difficult to achieve (and, in particular, the most difficult to add on after the system has been built) turn out to be precisely those that are architectural.
If you want to support the ability of a user to cancel an operation in progress, returning to the precise system state in place before the operation was started, you need to plan for this capability in the architecture. Likewise, if you want to support the ability of a user to undo a previous action and if you want to give the user feedback as to an operation's progress. There are many other examples.
The point here is that it is easy to assume that a quality attribute, or significant portions of a quality attribute, are not architectural. Not everything is architectural it's true, but frequently our assumptions of what is and what is not are based on a superficial analysis of the problem. Probe more deeply, and significant architectural considerations pop up everywhere. And woe to the architect (or architecture writer!) who ignores them.
- RK
|
Environment.
The user actions with which usability is concerned always occur at runtime or at system configuration time. Any action that occurs before then is performed by developers and, although a user may also be the developer, we distinguish between these roles even if performed by the same person. In Figure 4.8, the cancellation occurs at runtime.
Response.
The system should either provide the user with the features needed or anticipate the user's needs. In our example, the cancellation occurs as the user wishes and the system is restored to its prior state.
Response measure.
The response is measured by task time, number of errors, number of problems solved, user satisfaction, gain of user knowledge, ratio of successful operations to total operations, or amount of time/data lost when an error occurs. In Figure 4.8, the cancellation should occur in less than one second.
The usability general scenario generation table is given in Table 4.6.
Table 4.6. Usability General Scenario Generation
|
Source
|
End user
|
|
Stimulus
|
Wants to
learn system features; use system efficiently; minimize impact of errors; adapt system; feel comfortable
|
|
Artifact
|
System
|
|
Environment
|
At runtime or configure time
|
|
Response
|
System provides one or more of the following responses:
to support "learn system features"
help system is sensitive to context; interface is familiar to user; interface is usable in an unfamiliar context
to support "use system efficiently":
aggregation of data and/or commands; re-use of already entered data and/or commands; support for efficient navigation within a screen; distinct views with consistent operations; comprehensive searching; multiple simultaneous activities
to "minimize impact of errors":
undo, cancel, recover from system failure, recognize and correct user error, retrieve forgotten password, verify system resources
to "adapt system":
customizability; internationalization
to "feel comfortable":
display system state; work at the user's pace
|
|
Response Measure
|
Task time, number of errors, number of problems solved, user satisfaction, gain of user knowledge, ratio of successful operations to total operations, amount of time/data lost
|
COMMUNICATING CONCEPTS USING GENERAL SCENARIOS
One of the uses of general scenarios is to enable stakeholders to communicate. We have already pointed out that each attribute community has its own vocabulary to describe its basic concepts and that different terms can represent the same occurrence. This may lead to miscommunication. During a discussion of performance, for example, a stakeholder representing users may not realize that the latency of the response to events has anything to do with users. Facilitating this kind of understanding aids discussions of architectural decisions, particularly about tradeoffs.
Table 4.7. Quality Attribute Stimuli
|
Availability
|
Unexpected event, nonoccurrence of expected event
|
|
Modifiability
|
Request to add/delete/change/vary functionality, platform, quality attribute, or capacity
|
|
Performance
|
Periodic, stochastic, or sporadic
|
|
Security
|
Tries to
display, modify, change/delete information, access, or reduce availability to system services
|
|
Testability
|
Completion of phase of system development
|
|
Usability
|
Wants to
learn system features, use a system efficiently, minimize the impact of errors, adapt the system, feel comfortable
|
Table 4.7 gives the stimuli possible for each of the attributes and shows a number of different concepts. Some stimuli occur during runtime and others occur before. The problem for the architect is to understand which of these stimuli represent the same occurrence, which are aggregates of other stimuli, and which are independent. Once the relations are clear, the architect can communicate them to the various stakeholders using language that each comprehends. We cannot give the relations among stimuli in a general way because they depend partially on environment. A performance event may be atomic or may be an aggregate of other lower-level occurrences; a failure may be a single performance event or an aggregate. For example, it may occur with an exchange of severalmessages between a client and a server (culminating in an unexpected message), each of which is an atomic event from a performance perspective.

|